
Teaching students how to effectively and responsibly research can be challenging. We hope for well-developed bibliographies; our students might give us the top-ten hits in Google Scholar or JSTOR. ChatGPT is a new area of concern. The AI bot produces bibliographies in seconds, with no guarantee that the sources are relevant, or even real. I can’t keep ChatGPT out of my classroom; I can’t force my students to fall in love with interlibrary loans. But I can develop interactive lessons that challenge them to think about the quality and relevance of information they use.


This is where digital text analysis comes in, and I’m going demonstrate the process using the Argive Heraion sanctuary. I analyzed peer-reviewed articles that historians and archaeologists wrote about the Argive Heraion, using JSTOR’s Constellate lab.

The first step was going to Constellate’s Dataset Builder, where users can search JSTOR’s database. I searched for “argive heraion” OR “heraion of argos” OR “heraion at argos”; English; 1900–2023. I discovered 1,033 total documents, and could create basic visualizations: how many publications were produced per year; keywords in the corpus; frequency of specific terms used over time.
Ask yourself (or your students): does this body of work accurately represent all the people and institutions working on the Argive Heraion? It doesn’t. Looking at the first twenty-five records, it’s clear there are duplicates and documents where “Argive Heraion” (or a variant) is only mentioned briefly. Your students might be surprised to find imperfect search results. After all, they’re using a database with peer-reviewed sources, and yet, that doesn’t necessarily guarantee relevant information.
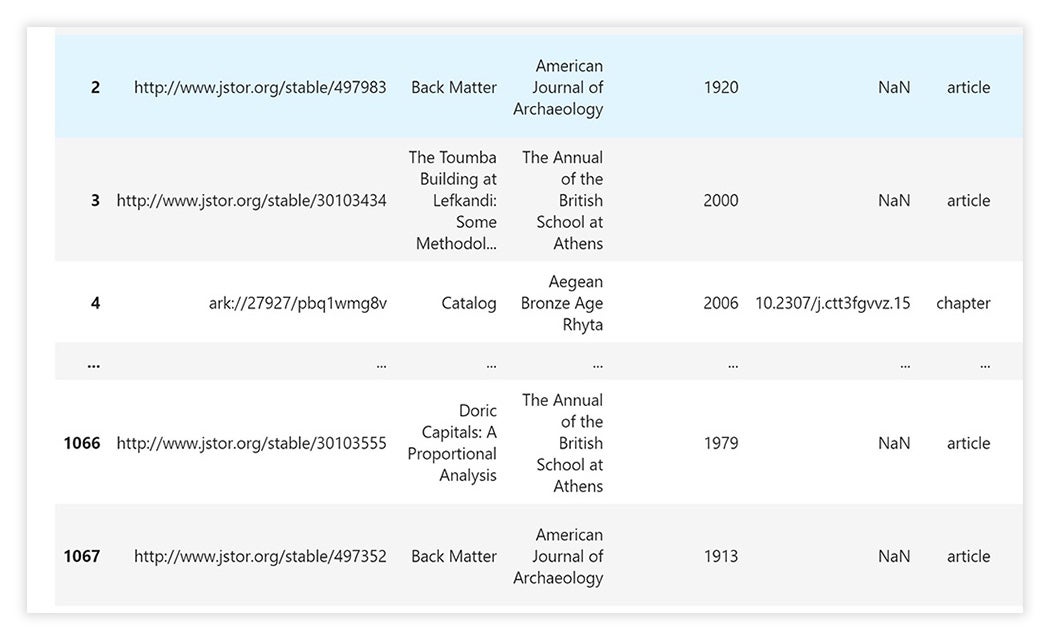
The Dataset Builder is powerful, but we can dig deeper with Constellate’s Jupyter lab notebooks. The lab supports Python scripts, with a variety of open educational resources for text analysis learning and research. Following the Constellate lab’s detailed guides, I learned how to import my Argive Heraion dataset (the aforementioned 1033 documents) into their Jupyter notebook. I used their Metadata Editing script to refine my dataset; 1033 documents transformed into 13 peer-reviewed articles or book chapters that explicitly mention “Argive Heraion” (or a variant) in the title.
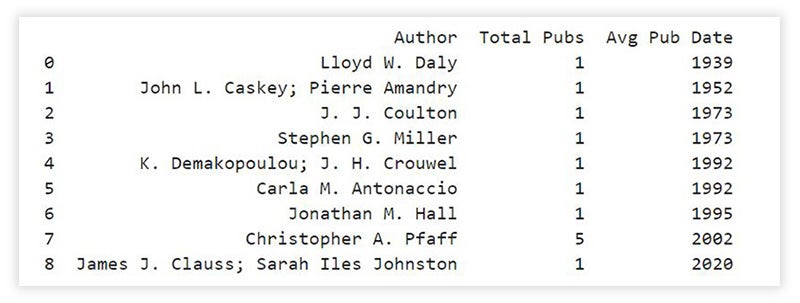
The Jupyter notebook helped automate this process and, after I identified faulty characteristics (e.g., documents that were bibliographies or indices), I could quickly remove multiple records at once. I was the one making decisions—not the machine—and I had to keep checking how removing certain documents affected the final analytical results.
If the Jupyter notebook is too time-intensive for your classroom, you can replicate this process in the Dataset Builder. Ask your students to scroll through the list of documents and have them develop specific rules for deciding what to keep.
Text analysis is a great way to model how information is consumed across different populations. Using Constellate, students can visualize the prevalence of particular keywords in their corpus. In my article about the Argive Heraion, I mentioned that ancient sources sometimes perpetuated propaganda and misinformation about the sanctuary’s history. Using the Jupyter notebook, I could search for propaganda-related terms: Kleobis, Cleobis, and Biton. Constellate revealed which documents contain the terms, and I could compare frequencies.
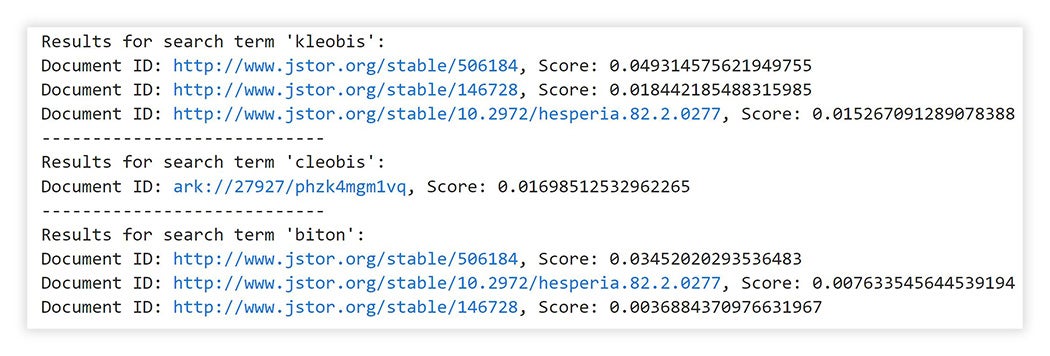
Of course, context matters; these numbers are meaningless without understanding precisely what the authors are saying about Kleobis and Biton.
We can turn the tables and investigate whether scholarly articles have infiltrated elsewhere. Ancient authors couldn’t possibly cite modern scholarly articles, but we can look at other bodies of writing. Because my research questions had to do with landmarks, I decided to look at modern tourist reviews from Trip Advisor and Google Maps. For your classroom, some other corpus might make sense: product reviews on Amazon; social media posts or forums; newspaper op-eds; or Wikipedia posts.
Whatever you choose, instruct your students to copy and paste the text into Voyant. Now, compare the Word Clouds: one constructed with peer-reviewed documents in Constellate, the second comprised of public interest writing in Voyant. These simple visualizations show frequently mentioned words, and when compared between different groups of authors, compelling questions arise: is peer-reviewed scholarship part of the public narrative? Are these groups interested in the same topics, and are they reframed? Constellate, Voyant, and other text analysis tools are designed for use in classrooms and scholarly research, and we can design innovative lessons that connect to today’s world. Today, students face a barrage of online content, but we can train them to scrutinize whatever digital information is presented to them. We can help them envision how information spreads across broad spans of time and space and recognize that an author’s sociocultural identity will inevitably shape the work they produce. We can empower our students to chase leads, hone bibliographies, and take analytical risks.
Constellate, Voyant, and other text analysis tools are designed for use in classrooms and scholarly research, and we can design innovative lessons that connect to today’s world. Today, students face a barrage of online content, but we can train them to scrutinize whatever digital information is presented to them. We can help them envision how information spreads across broad spans of time and space and recognize that an author’s sociocultural identity will inevitably shape the work they produce. We can empower our students to chase leads, hone bibliographies, and take analytical risks.
Support JSTOR Daily! Join our membership program on Patreon today.



